Leading Synthetic Data Platforms Vs Synthehol Platform: A Guide for Enterprise AI Teams

Synthehol targets the gap that most synthetic data platforms usually ignore. The tool is built for AI and AML teams which needs production grade data fidelity along with privacy. It needed an end-to-end observation into how the synthetic datasets affect the model training, evaluation, and downstream performance rather than just optimizing the row-level plausibility.
Synthehol primarily focused on preserving the joint distributions, long-tail behavior, and structural constraints while exposing measurable signals that help teams in monitoring the utility, drift, and risk when synthetic data moves through MLOps pipelines.
Why Synthetic Data Matters Now for AI Enterprises?
The data companies and AI enterprises are facing three major challenges, such as strict ‘no prod in nonprod’ policies, fragmented data estates, and blind spots around the rare but business-critical events like system outages and fraud spikes.
The synthetic data platforms help to handle such challenges. They learn statistical patterns from the sensitive data and generate data sets that are compliant with privacy. This allows the teams to train, test, and monitor the AI without the risk of violating data regulations.
The real difference between the tools is not generating synthetic data but proving the privacy, fidelity, and business utilization at enterprise scale.
Synthehol.ai: Design for High Fidelity Enterprise AI
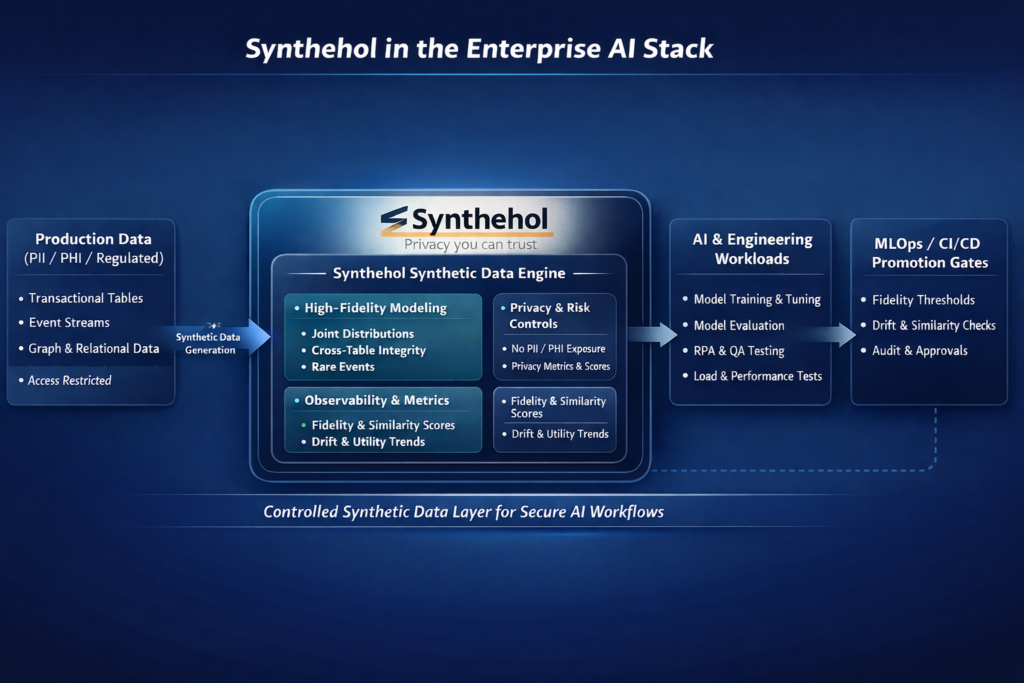
Synthehol is developed for enterprises using synthetic data in real AI systems; it is not just experimentation. The platform is positioned as the secured synthetic data platform for AI training, analytics, and QA in regulated environments. The tool is explicitly aligned with the GDPR, SOC-style controls, and HIPAA.
The core design philosophy is deliberately to change the data layer rather than changing the model layer to let the teams adapt models to degraded or masked data. Synthehol learns the generative representations with high-fidelity. It also preserves the joint distributions, correlations, and domain constraints while decoupling synthetic outputs from PHI and PII.
Key technical and product characteristics:
High-fidelity modeling of complex structures
Synthehol combines the distribution preservation and statistical techniques using deep generative modeling in order to maintain the realistic behavior across the relevant entities.
This is super important in the enterprise domains where the accuracy is based on the cross-table and cross-event consistency. Such claims are linked to the payments, policies, and users interacting with the multiple systems.
The Goal is not about the plausible rows, but a statistically and structurally coherent system, including the long-tail and rare events that standard datasets often miss.
Enterprise-grade observability
At Synthehol, the row counts, runtime, execution status, and every synthetic data generation are completely tracked. The activity feed records all the actions, including who initiated, what action, and when. It creates an auditable history of the synthetic data usage.
For the product, data, and risk teams, this helps in a single source of truth for the synthetic data sets and mirrors the observability and audit expectations that are applied to the production data platforms.
Quantified privacy, fidelity, and utility
AI leaders can go with policy-driven workflows, as every synthetic dataset is evaluated with explicit privacy, similarity, utility, and fidelity metrics. The trend lines help to check where to improve the new generations and to stabilize or drift the relative to defined targets.
Teams can define the promotion rules, like blocking movement to UAT unless the fidelity crosses the threshold. The similarity will stay within the acceptable bounds and integrate the checks directly into the CI/CD and MLOps pipelines.
Data Generation based on Edge case and scenario focus
Synthehol is designed to generate adverse failure scenarios, including fraud bursts, extreme usage patterns, and peak-load conditions. This helps teams to stress test the models and systems before they experience these conditions in production. This kind of capability is valuable for the SRE, fraud, and risk teams, where production data often underrepresents the scenarios that are very important on the operational front.
Enterprise AI use case coverage.
Synthehol platform supports the enterprise AI workloads covering model training, QA testing, and RPA. It also includes the automation of insurance claims, recommendations, personalization of the systems, and performance testing. Synthetic data can be engineered to mirror the production behavior closely without exposing the sensitive records and violation of access controls.
What does this mean in Practice?
For AI and Data leaders, Synthehol reframes the synthetic data from a tactical data science workaround into a top-level component of compliance, AI architecture, and enterprise security. It keeps synthetic data under the same standards of observability, fidelity, and governance as any production-grade system.
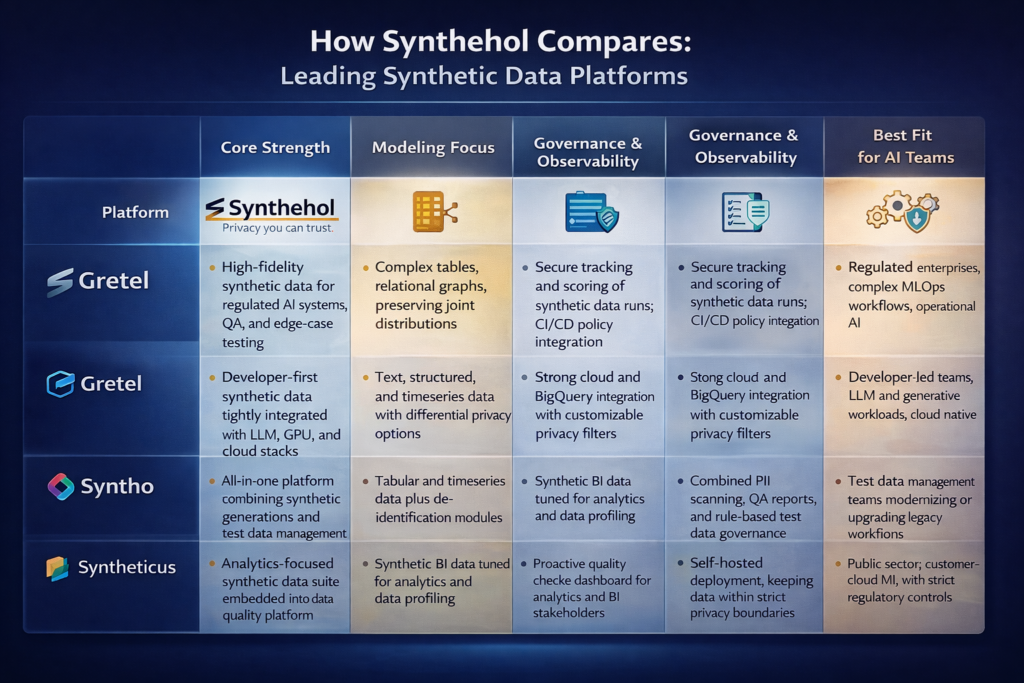
How Synthehol Compares To Leading Competitors? – Synthehol versus Other Data Platforms
AI enterprises are now checking the synthetic data platforms and shortlisting a small, well-defined set of vendors. While these platforms generate synthetic data, they are optimized for a variety of operating models, risk postures, and audiences.
Here is how Synthehol compares against commonly evaluated platforms like Gretel, Sytho, Sytheticus, and MOSTLY AI.
When Synthehol Is The Right Choice?
Synthehol is the best fit for data-driven and AI enterprises when synthetic data is not just a workaround, but you treat it as a control mechanism.
It will be aligned when:
If the work operates in regulated environments
If you work in insurance, healthcare, finance, or the public sector, you have to check that non-production environments never touch live PHI or PII, as Synthehol is designed for that realistic ecosystem. It helps teams to test the automation, validate systems, and train models on the data that behaves like production without any risk inheritance.
If your AI systems depend on complex data structures
Synthehol is perfectly suitable for AI systems built on multiple interdependent tables, graph-like relationships, and event streams. If broken referential integrity or unrealistic cross-entity behavior would invalidate your models
If you are planning to add synthetic data to your governance architecture
Yes, organizations that are looking for legal, risk, and security teams to get real visibility into synthetic data usage, Synthehol treats governance as a primary concern. The run-level metrics, quantitative privacy, and audit trails provide the line of sight and enforceable controls; other than that, informal assurances.
If edge cases matter more than the averages, Synthehol is for you.
If your business is based on handling rare but high-impact events like system failures, fraud spikes, and peak-load events, Synthehol can generate them deliberately at scale in those conditions deliberately at scale. This makes it valuable for the fraud, risk, and reliability-focused teams.
The Bottom Line
For AI enterprises that are building the critical models and automation on top of tightly regulated, access-controlled data estates and fragmented data, Synthehol stands out by combining production-grade observability, measurable privacy and task utility, and high-fidelity modeling. Combined, these capabilities transform the synthetic data from a tactical workaround into a top-level asset in the enterprise AI stack.
Want to try Synthehol or looking for an assisted demo? Try now or comment ‘Demo’ with your email address and our team will reach out to you.